I am an assistant professor of finance at the University of Chicago Booth School of Business. Much of my work leverages machine learning and natural language processing to address key questions in economics and finance. My current focus is on developing measures of beliefs with applications to asset pricing and behavioral economics.
Before Booth, I received a PhD in financial economics from the Yale School of Mangement, a master’s degree in statistics from the University of Michigan, and completed my undergraduate degree in economics at the University of Chicago.
Education
- Ph.D. in Financial Economics, Yale School of Management, 2024
- M.S. in Statistics, University of Michigan, 2017
- B.A. in Economics, University of Chicago, 2013
Publications
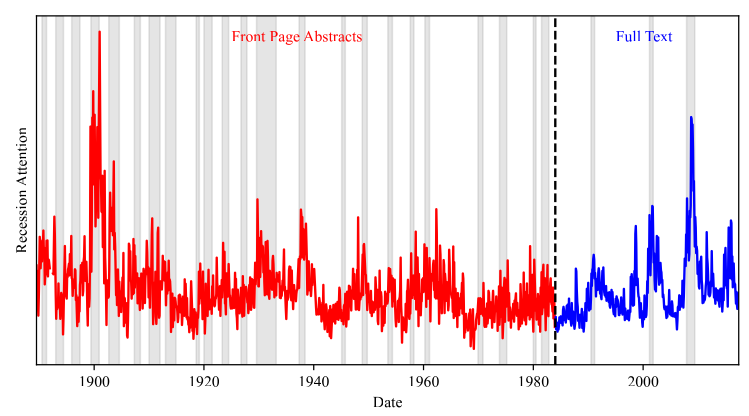
1. Business News and Business Cycles
(with Bryan Kelly, Asaf Manela, and Dacheng Xiu)
Journal of Finance
This version: April 2023
[Abstract] [PDF] [NBER] [SSRN] [Data]
Dimension Fund Advisors Distinguished Paper Award
We propose an approach to measuring the state of the economy via textual analysis of business news. From the full text of 800,000 Wall Street Journal articles for 1984–2017, we estimate a topic model that summarizes business news into interpretable topical themes and quantifies the proportion of news attention allocated to each theme over time. News attention closely tracks a wide range of economic activities and explains 25% of aggregate stock market returns. A text-augmented VAR demonstrates the large incremental role of news text in modeling macroeconomic dynamics. We use this model to retrieve the narratives that underlie business cycle fluctuations.
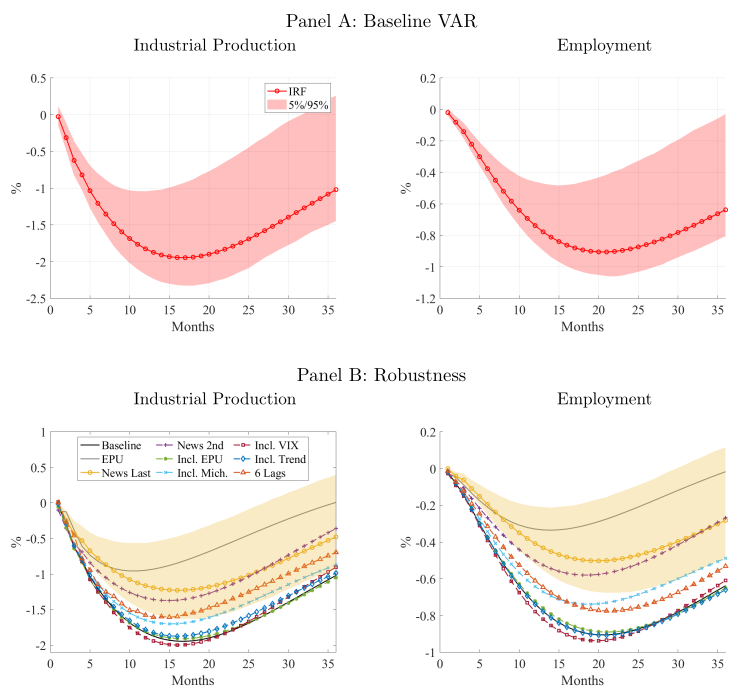
2. Narrative Asset Pricing: Interpretable Systematic Risk Factors from News Text
(with Bryan Kelly and Yinan Su)
Review of Financial Studies
This version: May 2023
[Abstract] [PDF] [RFS] [SSRN] [Code] [Data]
We estimate a narrative factor pricing model from news text of The Wall Street Journal. Our empirical method integrates topic modeling (LDA), latent factor analysis (IPCA), and variable selection (group lasso). Narrative factors achieve higher out-of-sample Sharpe ratios and smaller pricing errors than standard characteristic-based factor models and predict future investment opportunities in a manner consistent with the ICAPM. We derive an interpretation of the estimated risk factors from narratives in the underlying article text.
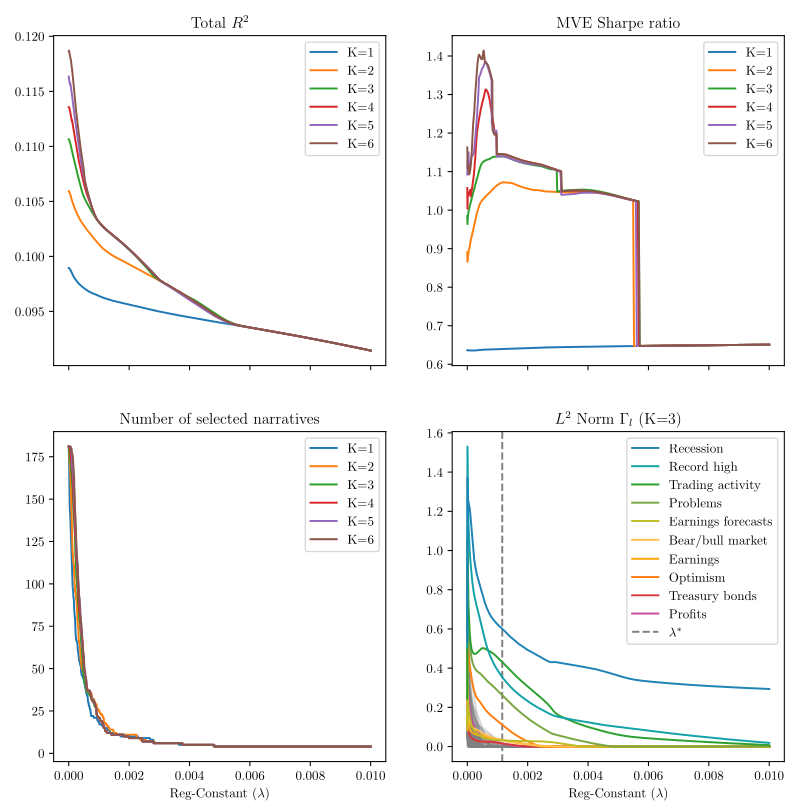
3. Change-point Computation for Large Graphical Models: A Scalable Algorithm for Gaussian Graphical Models with Change-points
(with Yves Atchadé)
Journal of Machine Learning Research
This version: January 2018
[Abstract] [PDF] [JMLR] [Code]
Graphical models with change-points are computationally challenging to fit, particularly in cases where the number of observation points and the number of nodes in the graph are large. Focusing on Gaussian graphical models, we introduce an approximate majorize- minimize (MM) algorithm that can be useful for computing change-points in large graphical models. The proposed algorithm is an order of magnitude faster than a brute force search. Under some regularity conditions on the data generating process, we show that with high probability, the algorithm converges to a value that is within statistical error of the true change-point. A fast implementation of the algorithm using Markov Chain Monte Carlo is also introduced. The performances of the proposed algorithms are evaluated on synthetic data sets and the algorithm is also used to analyze structural changes in the S&P 500 over the period 2000-2016.
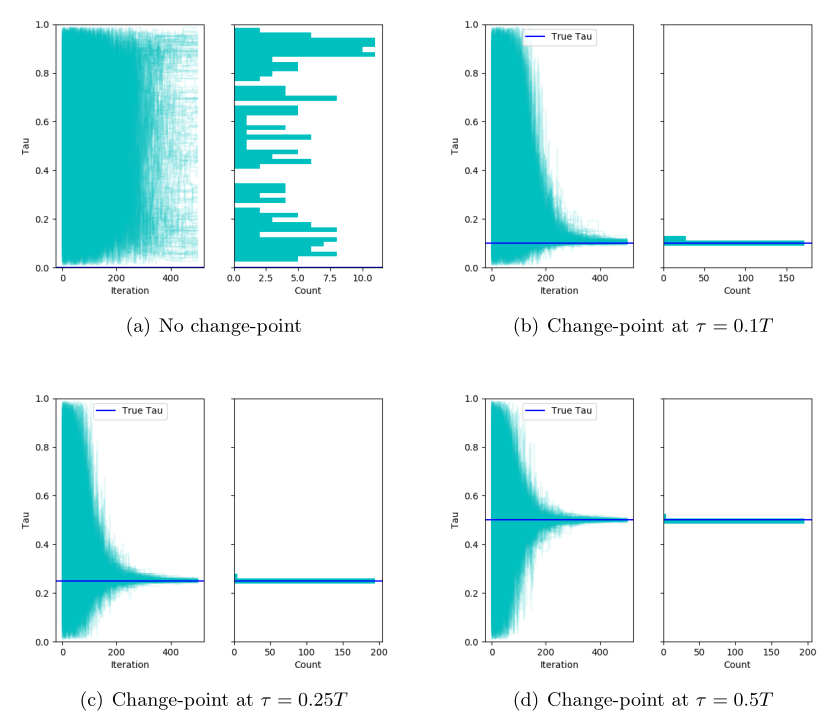
Working Papers
4. The Ghost in the Machine: Generating Beliefs with Large Language Models
This version: February 2025
[Abstract] [PDF]
BlackRock Applied Research Award
HEC Top Finance Graduate Award
The Brattle Group PhD Candidates Awards for Outstanding Research
EFA Engelbert Dockner Memorial Prize for the Best Paper by Young Researchers
Subsumes Surveying Generative AI’s Economic Expectations
I introduce a methodology to generate economic expectations by applying large language models to historical news. Leveraging this methodology, I make three key contributions. (1) I show generated expectations closely match existing survey measures and capture many of the same deviations from full-information rational expectations. (2) I use my method to generate 120 years of economic expectations from which I construct a measure of economic sentiment capturing systematic errors in generated expectations. (3) I then employ this measure to investigate behavioral theories of bubbles. Using a sample of industry-level run-ups over the past 100 years, I find that an industry's exposure to economic sentiment is associated with a higher probability of a crash and lower future returns. Additionally, I find a higher degree of feedback between returns and sentiment during run-ups that crash, consistent with return extrapolation as a key mechanism behind bubbles.
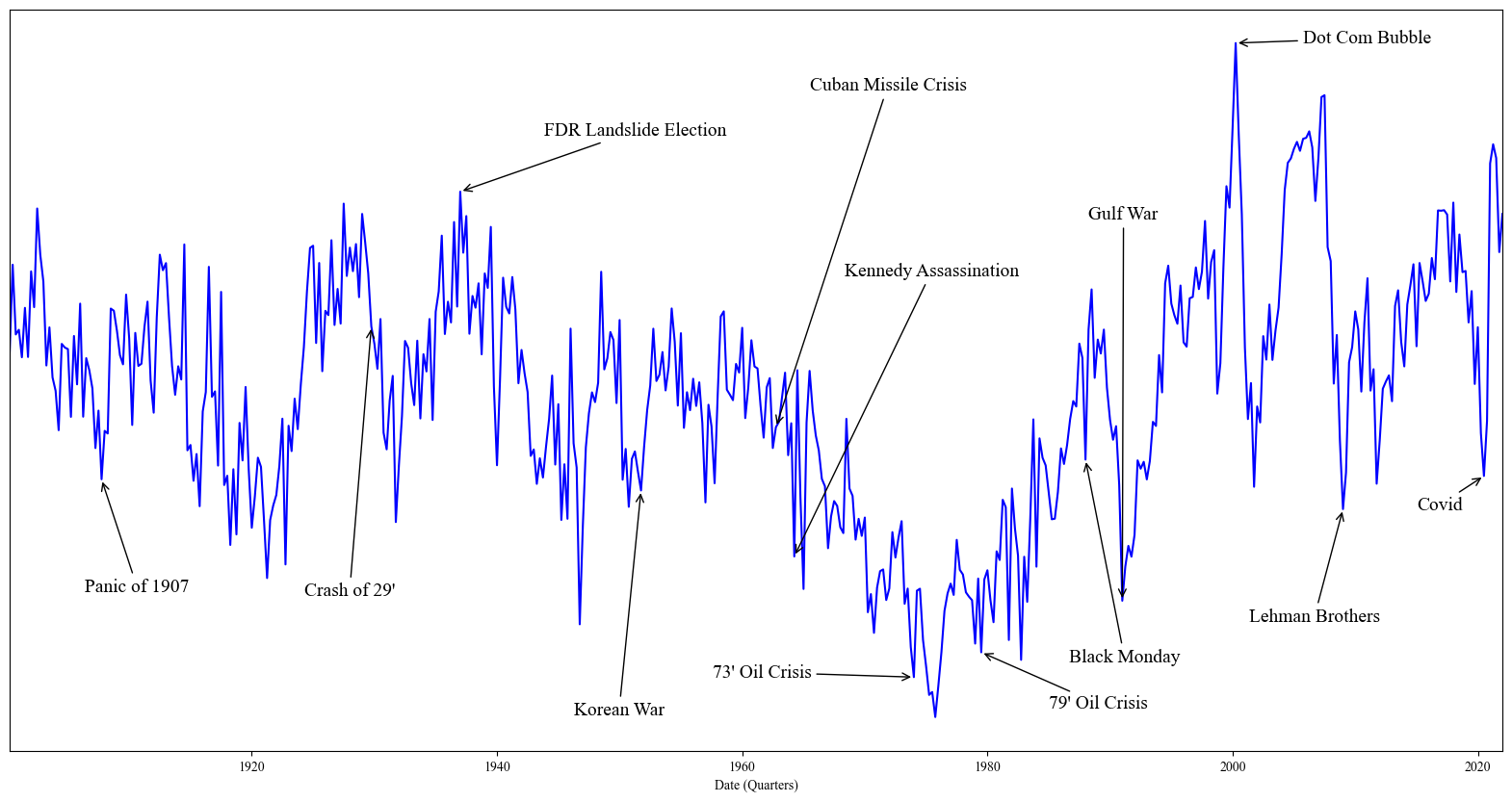
5. Associative Memory is Machine Learning
(with Tianshu Lyu)
This version: September 2023
[Abstract]
We document a relationship between memory-based models of beliefs and a general class of kernel methods from the statistics and machine learning literature. Motivated by this relationship, we propose a new form of memory-based beliefs which aligns more closely with the state of the art in the machine learning literature. We explore this approach empirically by introducing a measure of "narrative memory" -- similarity between states of the world based on similarity in narrative representations of those states. Using textual embeddings extracted from conference call transcripts, we show that our estimates of memory-based beliefs explain variation in errors in long-term growth forecasts of IBES analysts. We conclude by discussing implications of this relationship for the literature on memory-based models of beliefs.
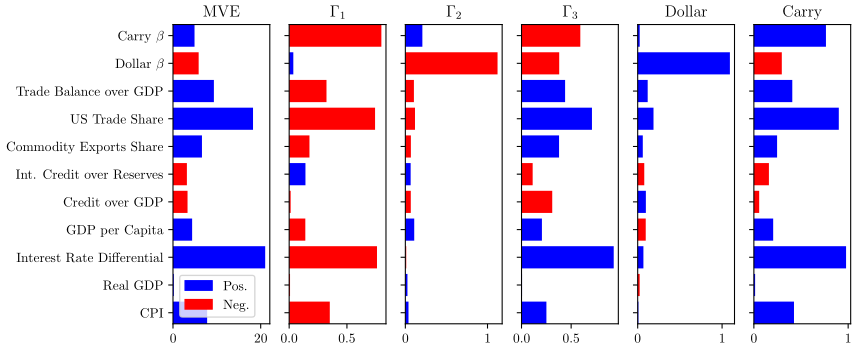
6. Macro-based Factors for the Cross-Section of Currency Returns
(with Leandro Gomes and Joao Valente)
This version: May 2023
[Abstract] [PDF] [SSRN] [Code]
We use macroeconomic characteristics and exposures to Carry and Dollar as instruments to estimate a latent factor model with time-varying betas with the instrumented principal components analysis (IPCA) method by Kelly et al. (2020). On a pure out-of-sample basis, this model can explain up to 78% of cross-sectional variation of a Global panel of currencies excess returns, compared to only 27.9% for Dollar and Carry and 51% for a static PCA model. The latent factor and time-varying exposures are directly linked to macroeconomic fundamentals. The most relevant are exports exposures to commodities and US trade, credit over GDP, and interest rate differentials. This model, therefore, sheds light on how to incorporate macroeconomic fundamentals to explain time-series and cross-section.
Code & Data
regIPCA
A penalized implementation of instrumented principal components analysis in Python.
The Structure of Economic News
Data and summaries for the 180 topics estimated for Business News and Business Cycles.
DiSTL
A collection of efficient Gibbs sampling implementations for latent Dirichlet allocation in Python.
glVAR
A fast method for group lasso vector autoregression in Python.
labbot
A set of Python decorators useful for iterative development of research code.
IPCA
A Python implementation of instrumented principal components analysis (with Matthias Buchner).
statsmodels
I contributed the distributed estimation procedure of Lee et al. (2015) for penalized estimators.
changepointsHD
An R implementation of a simulated annealing algorithm for change-point detection.
